Zimage Turbo Beats FLUX 2: Local AI Image Generation

Zimage Turbo Sets a New Baseline for Local Image Generation
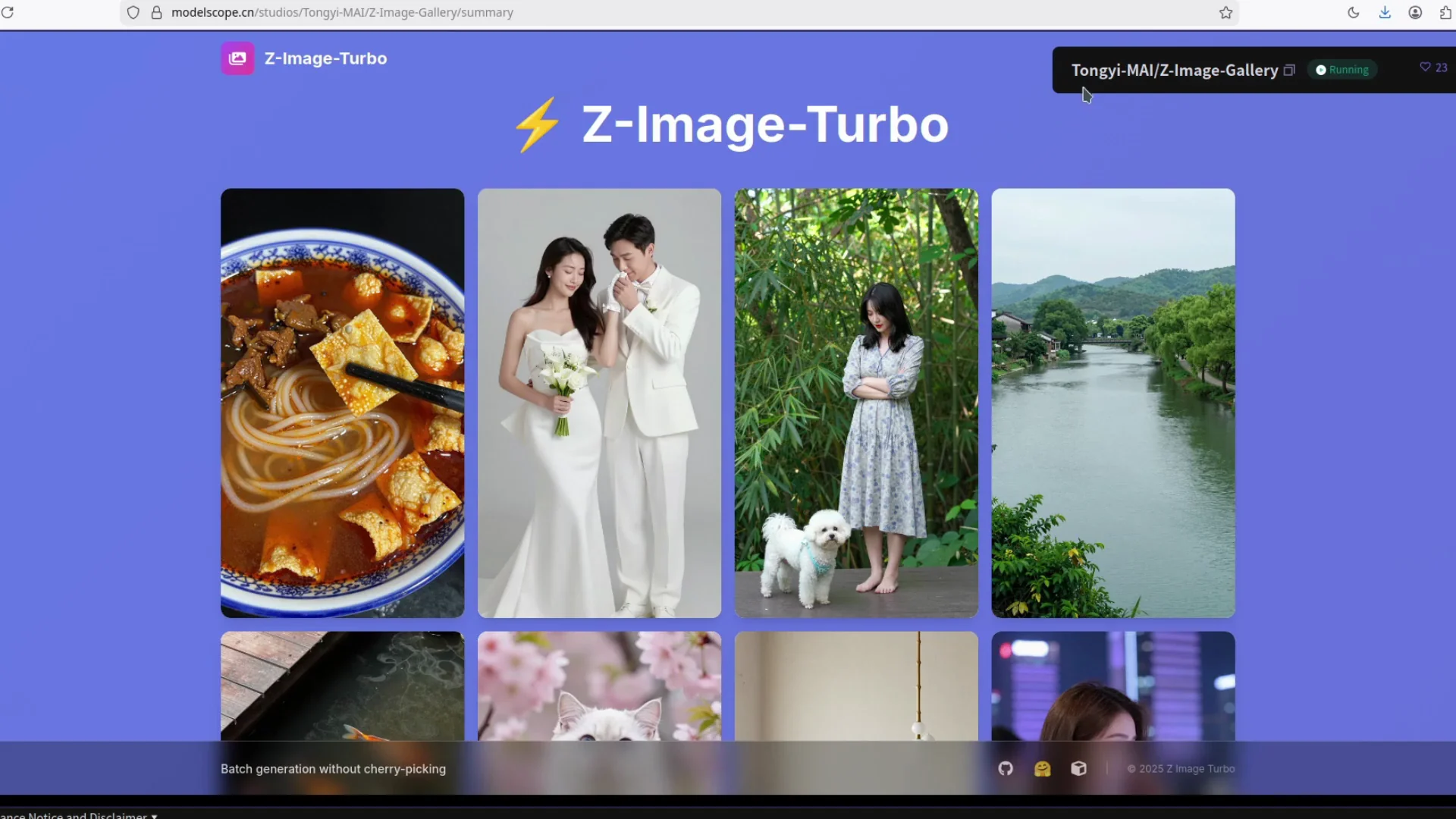
We have a new image model in town. It is Zimage Turbo, an AI image model from Tong Yi or Alibaba, and it is really good. I will share the workflow at the end, but first I want to show what it can do and how to run it locally with ComfyUI.
Visual Quality and Subject Coverage
Zimage Turbo produces realistic results with strong textures and clean anatomy. It handles animals, humans, and objects without obvious flaws. Fine details are present, including small hairs and surface texture that usually trip up smaller models. It also handles text rendering well.
Parameter Count and Hardware Needs
Zimage Turbo has 6 billion parameters. In contrast, with the current direction from Black Forest Labs in Flux Land, you need an H100 GPU with CPU offloading just to run inference. Zimage Turbo only needs a moderate to low-end graphics card, and that is enough for local generation.
What You Need to Download From Hugging Face
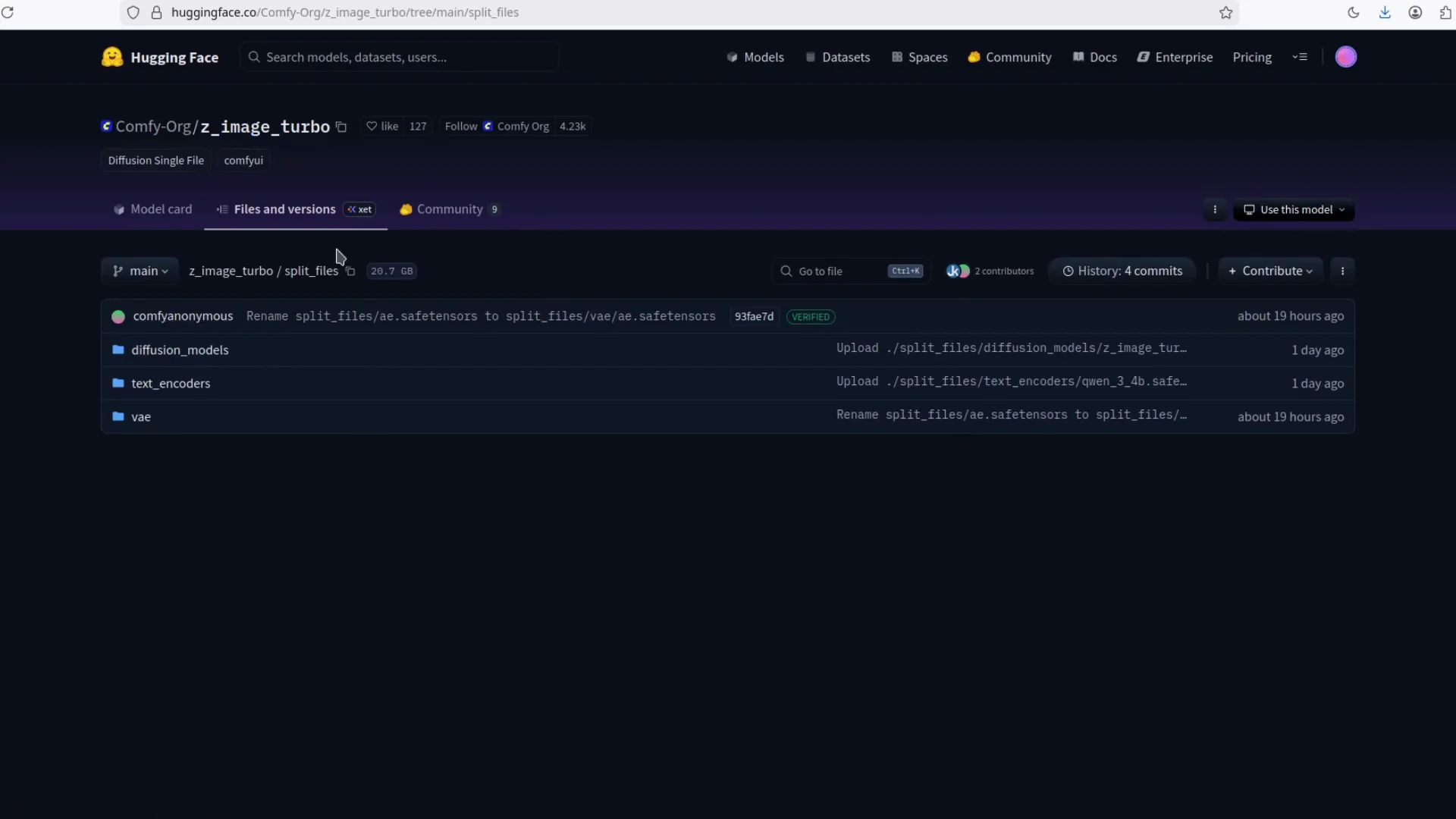
The model files are already on Hugging Face. You need three pieces to run Zimage Turbo properly in ComfyUI: the diffusion model, a text encoder, and a VAE.
- Diffusion model - get the full model. You can run this one directly.
- Text encoder - Zimage Turbo uses Qwen 3 with 4 billion parameters. I have tested it before and compared it with Qwen 2.5. Qwen 3 is on another level even with smaller parameters, and it should consume less VRAM.
- VAE - download the VAE and place it in the right folder.
Folder Placement for ComfyUI
Put each file in the correct ComfyUI folder. This is simple and important so the workflow can find the models automatically.
| Component | What it is | Destination folder in ComfyUI |
|---|---|---|
| Diffusion model | The main Zimage Turbo diffusion checkpoint | ComfyUI/models/checkpoints |
| Text encoder | Qwen 3 - 4B text encoder | ComfyUI/models/text_encoders |
| VAE | Variational Autoencoder for decoding latents | ComfyUI/models/vae |
Notes:
- If your ComfyUI setup uses different folder names, match them accordingly, but keep the same structure concept: checkpoints for diffusion, text_encoders for encoders, vae for the VAE.
- Do not mix multiple VAEs with the same name. Make sure the file names are clear and you select the intended VAE in the workflow.
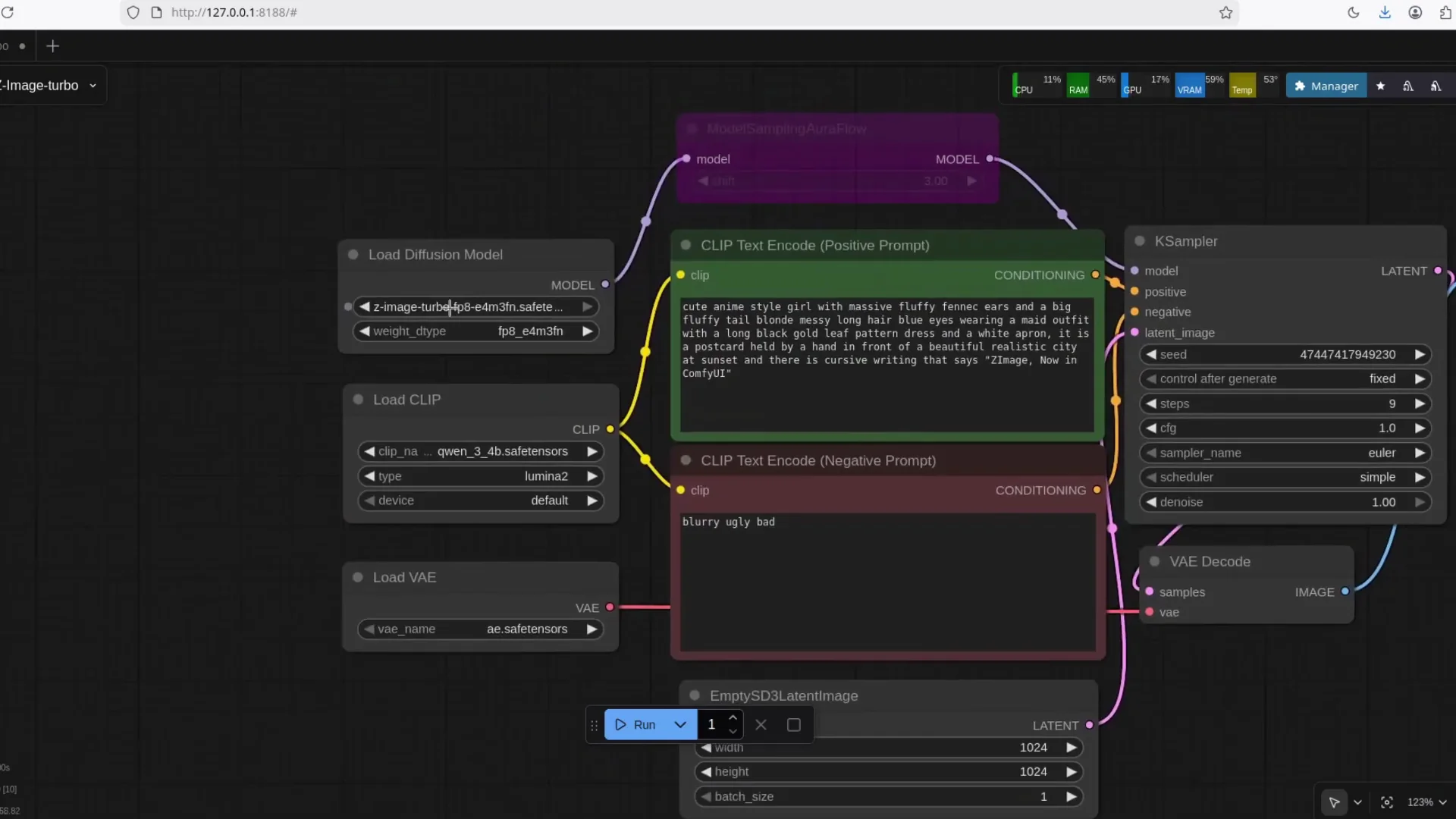
The Official ComfyUI Workflow
There is an official workflow for Zimage Turbo. Save the workflow image and drag and drop it into ComfyUI. That automatically builds the node graph. After that, point the nodes to the model files you downloaded.
- Save the official workflow image.
- Open ComfyUI.
- Drag the workflow image into the ComfyUI canvas.
- Check that the model nodes reference:
- The full Zimage Turbo diffusion model.
- The Qwen 3 - 4B text encoder.
- The VAE you downloaded.
FP8 Variant for Lower VRAM
I am using the FP8 version of the model. It is smaller and still produces strong results. I will include a link for the FP8 build along with the main files. Quality holds up well even in FP8, and it makes local generation more feasible on a modest GPU.
- FP8 reduces memory use.
- With FP8, text generation looks solid and I am not spotting flaws.
- If you are tight on VRAM, start with FP8.
Zimage Turbo - Text Rendering and Fidelity
Zimage Turbo handles text inside the image well. Even with the FP8 variant, text output looks clean. In my runs, I saw no issues with letters, curves, or spacing. Quality is consistent across subjects, and textures remain detailed.
If you have had issues with text rendering in other models, Zimage Turbo is worth a try. It produces readable text while maintaining overall image fidelity.
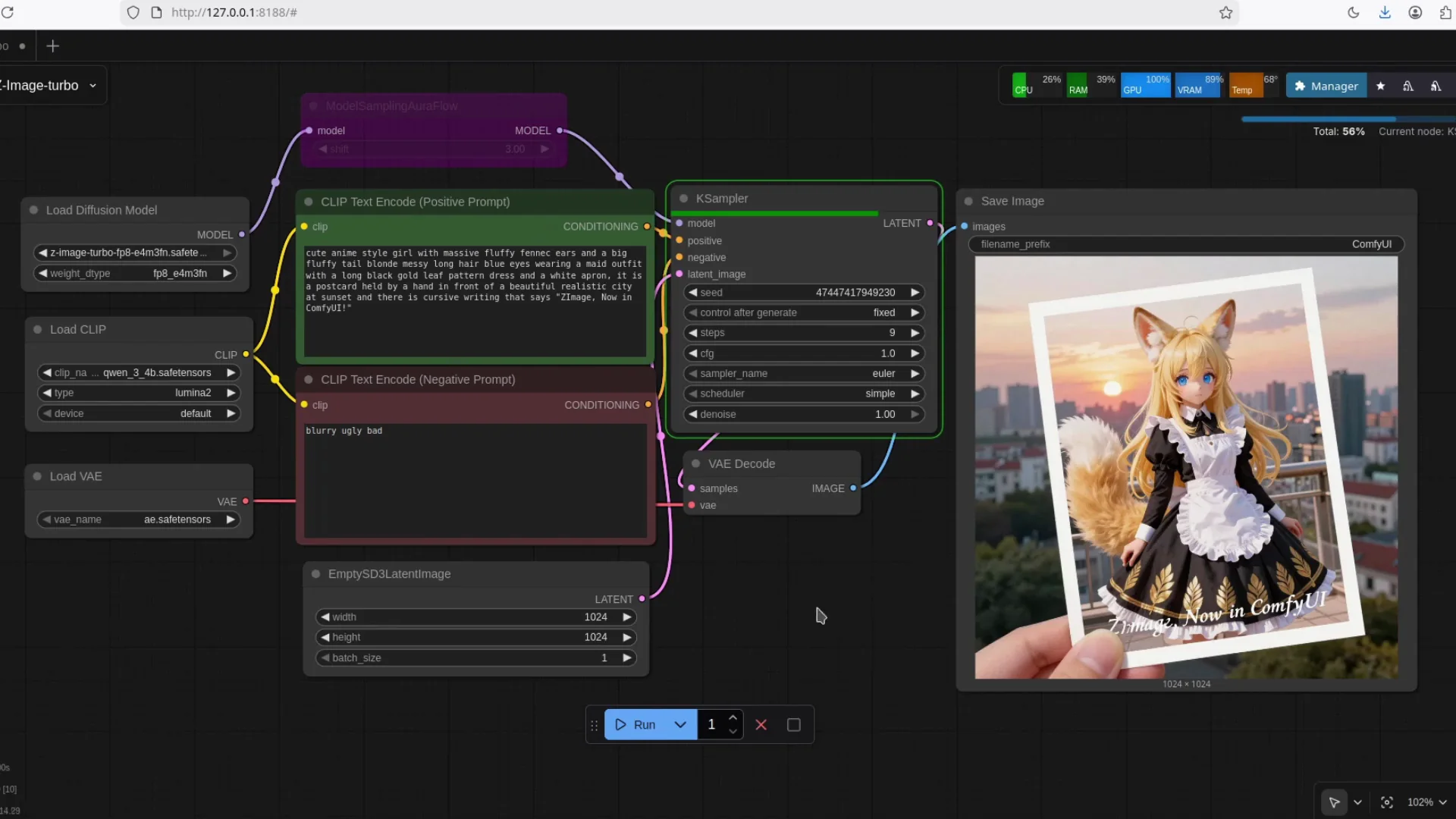
Performance - Speed on a Modest GPU
Zimage Turbo runs fast. To give a sense of speed, I ran a generation and watched the process:
- It starts encoding.
- It moves into generation.
- Progress reaches 50 percent quickly.
- This is with no special acceleration enabled.
- If you enable optimizations like sage attention, it should be much faster.
Even without tuning, the model feels responsive. With tuning, you can push throughput further and reduce latency.
Acceleration Options
If you want more speed:
- Enable attention optimizations such as sage attention.
- Use lower precision builds like FP8 for reduced VRAM pressure.
- Keep your ComfyUI updated so you have the latest performance improvements.
These are optional. The point is that Zimage Turbo runs well even without extra acceleration, which is a contrast to heavy setups that demand top-tier hardware.
Model Components - Why Each Part Matters
Zimage Turbo relies on three core components to deliver quality:
-
Diffusion model
- The main image generation brain. It contains the learned weights for denoising and structure. You must match this to the workflow.
-
Text encoder - Qwen 3 - 4B
- Converts your prompts into embeddings. Qwen 3 is a strong pick for this role. In my tests it outperforms Qwen 2.5 while using fewer parameters, which helps VRAM usage.
-
VAE
- Translates between latent space and pixel space. A good VAE preserves detail and texture. Make sure you use the intended VAE for Zimage Turbo.
Local Generation vs Heavy Server Requirements
Here is the practical contrast:
-
FLUX 2 direction
- H100 class GPU needed.
- CPU offloading for inference.
- Suited to very high-end hardware.
-
Zimage Turbo approach
- Runs on a moderate to low-end GPU.
- No special server setup required.
- FP8 option makes it easier to fit into limited VRAM.
This is why I consider Zimage Turbo a strong pick for local workflows today.
Step by Step - Install and Run Zimage Turbo in ComfyUI
Follow this checklist in order. Keep the same order to avoid missing dependencies.
- Prepare ComfyUI
- Install ComfyUI on your system.
- Confirm you can open the app and load a basic workflow.
- Download the Zimage Turbo files from Hugging Face
- Diffusion model - full model checkpoint.
- Text encoder - Qwen 3 - 4B.
- VAE - the recommended VAE for Zimage Turbo.
- Optional - Download the FP8 variant
- If you want smaller memory usage, get the FP8 build of the diffusion model.
- Keep both files if you plan to compare quality.
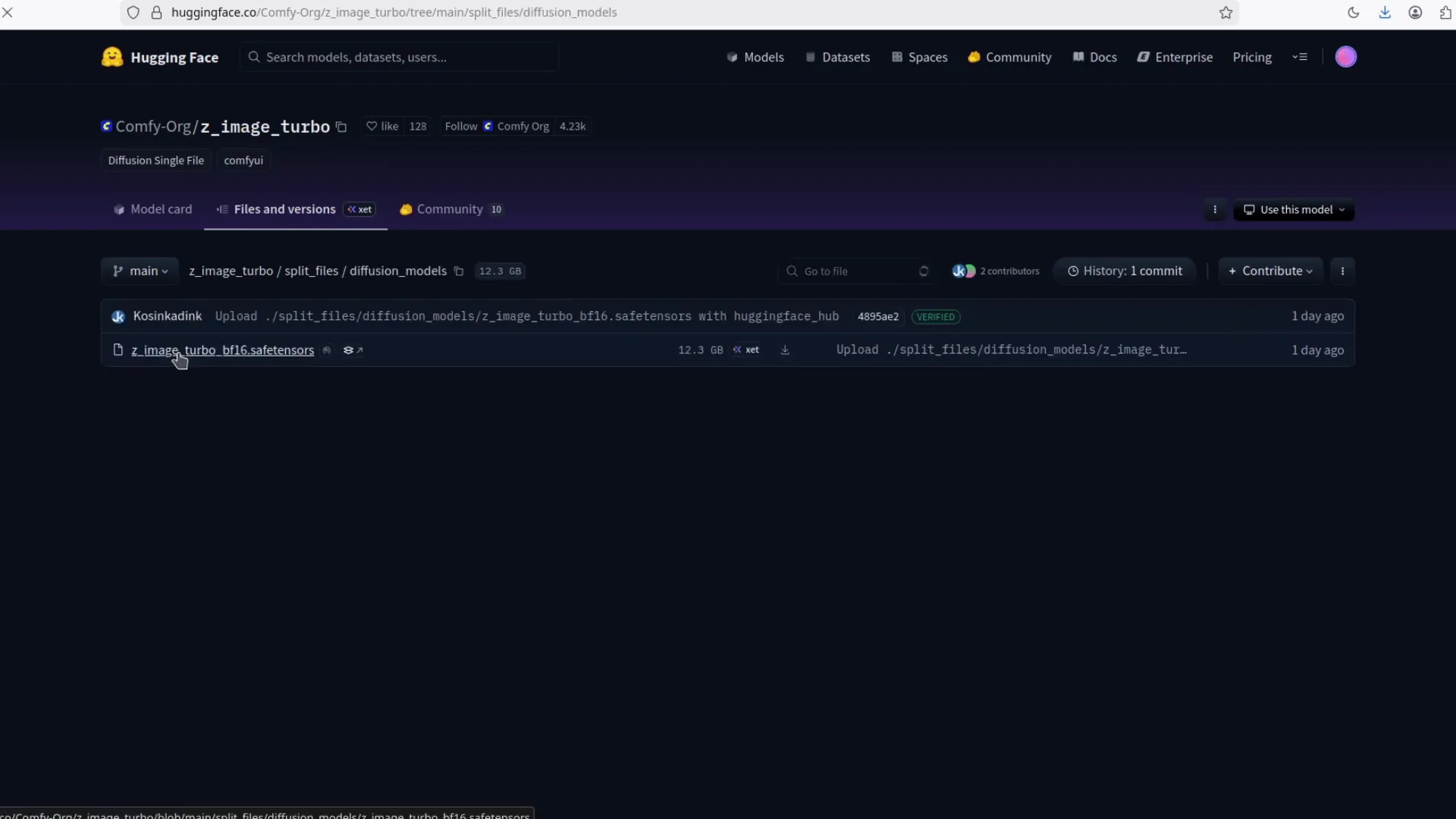
- Place files into ComfyUI folders
- Diffusion model -> ComfyUI/models/checkpoints
- Text encoder -> ComfyUI/models/text_encoders
- VAE -> ComfyUI/models/vae
- Load the official Zimage Turbo workflow
- Save the workflow image.
- Drag it into the ComfyUI canvas.
- Check all file paths in the nodes.
- Configure your settings
- Select the diffusion model you want to run.
- Select the Qwen 3 - 4B text encoder.
- Select the VAE.
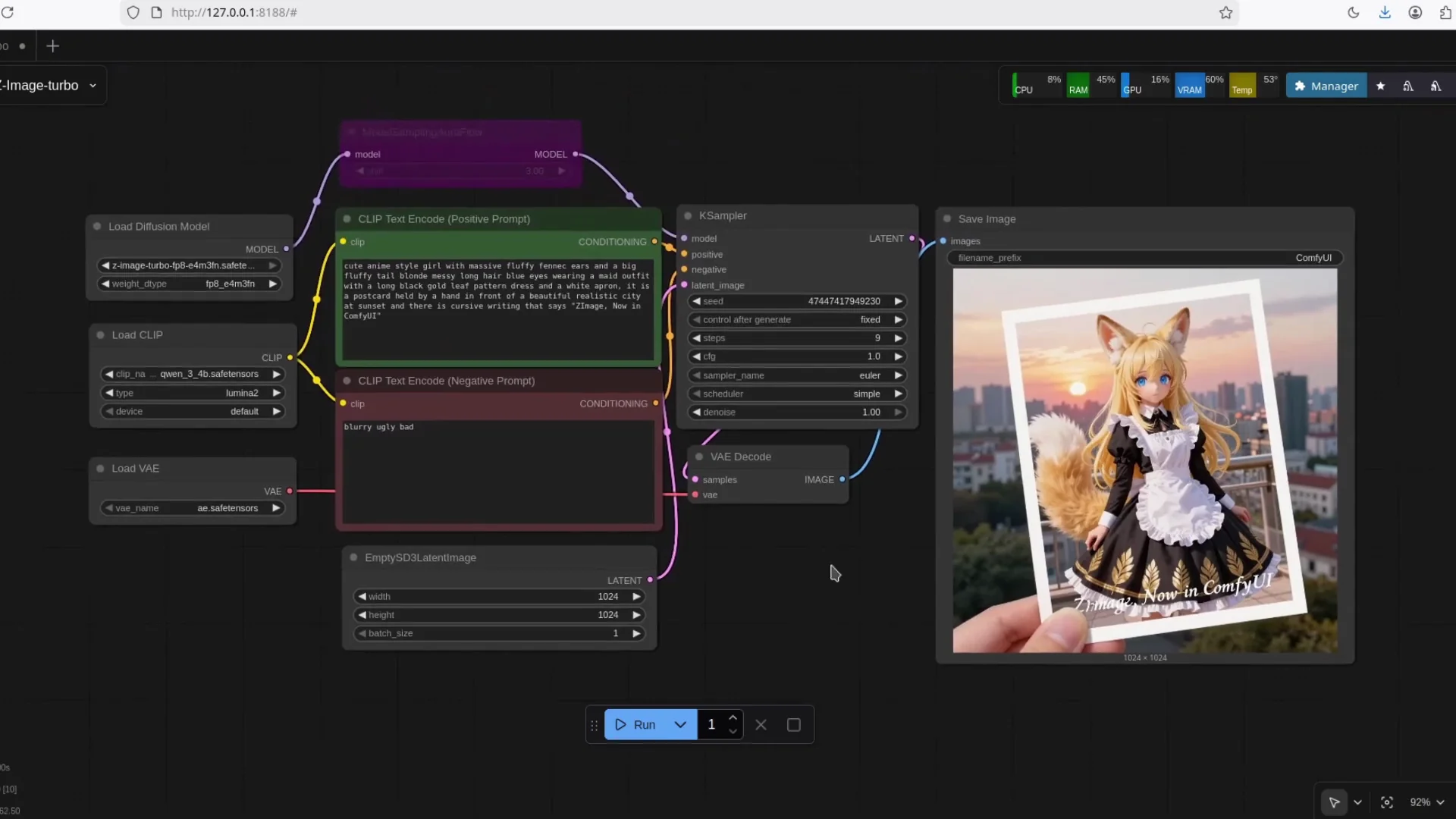
- Run a test generation
- Use a short prompt.
- Confirm encoding starts, then generation proceeds.
- Watch the progress. You should see quick movement to 50 percent.
-
Optional - Turn on acceleration
- Enable sage attention if available in your setup.
- Try lower steps or faster samplers if you need more throughput.
-
Inspect results
- Check text rendering inside the image if that matters to your use case.
- Check surface texture and anatomy.
-
Save the workflow and settings
- Keep a copy of the working graph.
- Document which versions of each component you used.
FP8 - Practical Notes
If you pick FP8:
- Expect lower VRAM usage and faster loads.
- Quality holds up well with Zimage Turbo. I am not seeing obvious regressions in text or anatomy.
- This is a good default for midrange GPUs.
If you have extra VRAM and want to compare, keep the full precision model as a second option and switch between them in the workflow.
Prompts and Text - What I Am Seeing
Zimage Turbo does text well. It renders letters cleanly. In back-to-back runs, text looked even better on subsequent attempts. If text accuracy is important to your workflow, it is worth testing Zimage Turbo first before trying heavier models.
Reliability Across Subjects
The model covers:
- Animals, including cats.
- Humans.
- Objects.
Texture reproduction is consistent. Small fibers, hair, and surface detail remain intact. Anatomy holds up without strange artifacts.
VRAM Awareness and Practical Limits
Because Zimage Turbo is 6B and supports FP8, it fits into setups that would struggle with larger models. If you had to rely on server hardware before, this model makes local work more realistic on consumer GPUs. If you are running into memory errors, check that:
- You selected the FP8 build.
- You closed other GPU-heavy applications.
- You reduced image size or steps temporarily to test.
Workflow Tips in ComfyUI
To keep runs smooth:
- Keep node inputs clean. Do not point at missing files.
- Verify model names match the files you downloaded.
- If a node shows an error, reselect the model from the dropdown so ComfyUI refreshes the path.
- Save a known-good workflow version before experimenting.
Troubleshooting Checklist
If your generation stalls or fails:
- Recheck that the diffusion model is in the checkpoints folder.
- Confirm the text encoder is Qwen 3 - 4B and is in the text_encoders folder.
- Confirm the VAE file is in the vae folder and selected in the workflow.
- If you are on very low VRAM, switch to the FP8 variant.
- Reduce output resolution to test stability.
- Disable optional accelerations to isolate the issue, then re-enable one by one.
Why Qwen 3 - 4B
Qwen 3 - 4B is a strong text encoder choice here. In my testing, it beats Qwen 2.5 and uses fewer parameters. That means less VRAM consumed by the encoder itself. You get better conditioning for prompts without the overhead of a larger encoder.
Observations on Model Quality
- Text - solid, clean, readable.
- Anatomy - no obvious flaws in the samples I generated.
- Texture - detailed, small elements show up well.
- Subjects - flexible across animals, people, and objects.
These are the key factors that matter for practical, daily use.
Speed Summary
- Starts quickly.
- Encodes and moves into generation without delay.
- Reaches 50 percent promptly.
- Finishes fast even without special acceleration.
- Can be faster with sage attention.
You do not need to change your system dramatically to get good speed from Zimage Turbo.
Files and Workflow - What I Am Sharing
The workflow and models are the essentials you need:
- The official workflow image for ComfyUI.
- The main Zimage Turbo diffusion model.
- The Qwen 3 - 4B text encoder.
- The VAE.
- The FP8 variant link.
These are the pieces I recommend downloading first so you can reproduce my results.
Zimage Turbo Context and Closing Notes
Zimage Turbo is strong enough that it makes heavy FLUX 2 style requirements feel out of reach for local users. This model does not ask for an H100 or complicated CPU offloading. You can run it with a moderate to low-end GPU, and the FP8 build makes it even more accessible.
Once again, the Chinese models are beating the Western models.
Quick Reference - Setup at a Glance
- Get the diffusion model, Qwen 3 - 4B text encoder, and VAE from Hugging Face.
- Put them into:
- checkpoints for the diffusion model
- text_encoders for Qwen 3 - 4B
- vae for the VAE
- Load the official workflow by dragging the workflow image into ComfyUI.
- Select the FP8 variant if you want lower VRAM usage.
- Run a test prompt and confirm encoding and generation proceed without errors.
- Optionally enable sage attention for added speed.
Links
- Zimage Turbo diffusion model - full model
- Zimage Turbo diffusion model - FP8 variant
- Qwen 3 - 4B text encoder
- VAE for Zimage Turbo
- Official Zimage Turbo ComfyUI workflow image
Recent Posts

How to Improve Text on Z-Image Turbo?
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image-De-Turbo de-distilled variant of Z-Image
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image Turbo ControlNet Workflow
Tutorial on Union ControlNet in ComfyUI—pose, Canny, and depth controls, depth-model preprocessing, step-by-step workflow, plus speed tests with example results.
Comments
Loading comments...