Z-image Turbo on Low VRAM: Fast 8-Step ComfyUI Workflow

This guide walks through Z-Image-Turbo, a distilled image model and workflow that produces high quality images in about eight steps on low VRAM hardware. I will explain the architecture in simple terms, show the exact setup in ComfyUI, and share notes on speed, VRAM use, and reliability based on direct testing.
The workflow focuses on stable results with the FP8 checkpoint, fast generation on 8 GB GPUs, and correct configuration of the text encoder and CLIP settings. By the end, you will be able to load the workflow, set the correct components, and produce images in seconds.
What is Z-Image-Turbo?
Z-Image-Turbo is a distilled version of the Z-image model designed to match or exceed top models using only eight function evaluations. In practice, it can generate strong outputs in about eight sampling steps.
The model adopts a scalable single-stream DiT architecture. Text and image tokens are concatenated into one unified sequence before inference. This approach improves parameter efficiency compared to dual-stream pipelines.
In testing, it consistently produced images in 30 seconds or less on 8 GB of VRAM, with many renders finishing closer to 13 seconds. At the time of testing, it was ranked number four on a public benchmark, which matches the strong performance observed during evaluation.
Z-Image-Turbo Overview
The notes below summarize the model, hardware needs, and the working ComfyUI setup used for testing.
| Category | Details |
|---|---|
| Model type | Distilled image model based on a single-stream DiT architecture |
| Generation steps | About 8 steps per image |
| Speed target | Typically under 30 seconds on 8 GB VRAM, often around 13 seconds |
| VRAM target | 8 GB GPUs |
| Checkpoint variant | FP8 recommended for stability |
| Checkpoint size | FP8 model is about 6 GB |
| Alternative checkpoint | BF16 caused black images during testing |
| Text encoder | Can demand around 8 GB of VRAM |
| CLIP requirement | CLIP type must be set to Lumina 2 |
| CLIP file backing | Runs on the Qwen 3B CLIP file |
| Workflow host | ComfyUI |
| Node setup | Diffusion model, sampling flow, VAE, CLIP, two text encoders, KSampler, empty latent, decode, save image |
| Benchmark note | Ranked number four during testing on a public analysis site |
Key Features of Z-Image
- Eight-step generation that matches or exceeds strong baselines
- Single-stream token setup for parameter efficiency
- Very fast image creation on 8 GB GPUs
- FP8 checkpoint that fits easily into low VRAM budgets
- Consistent text rendering in images like billboards and signage
- Reliable outputs across common test scenes and portraits
How to Use Z-Image-Turbo? (Step-by-Step Guide)
Follow these steps to set up and run the workflow in ComfyUI.
1. Download the workflow and model files
- Get the ComfyUI workflow and required model files from the linked CivitAI workflow page.
- Use the FP8 model variant. BF16 produced black images during testing.
- Note the checkpoint size: the FP8 file is about 6 GB.
2. Be aware of VRAM needs
- The FP8 checkpoint fits comfortably in most low VRAM setups.
- The text encoder can require around 8 GB of VRAM. If you have exactly 8 GB, close other GPU applications and keep batch size to 1.
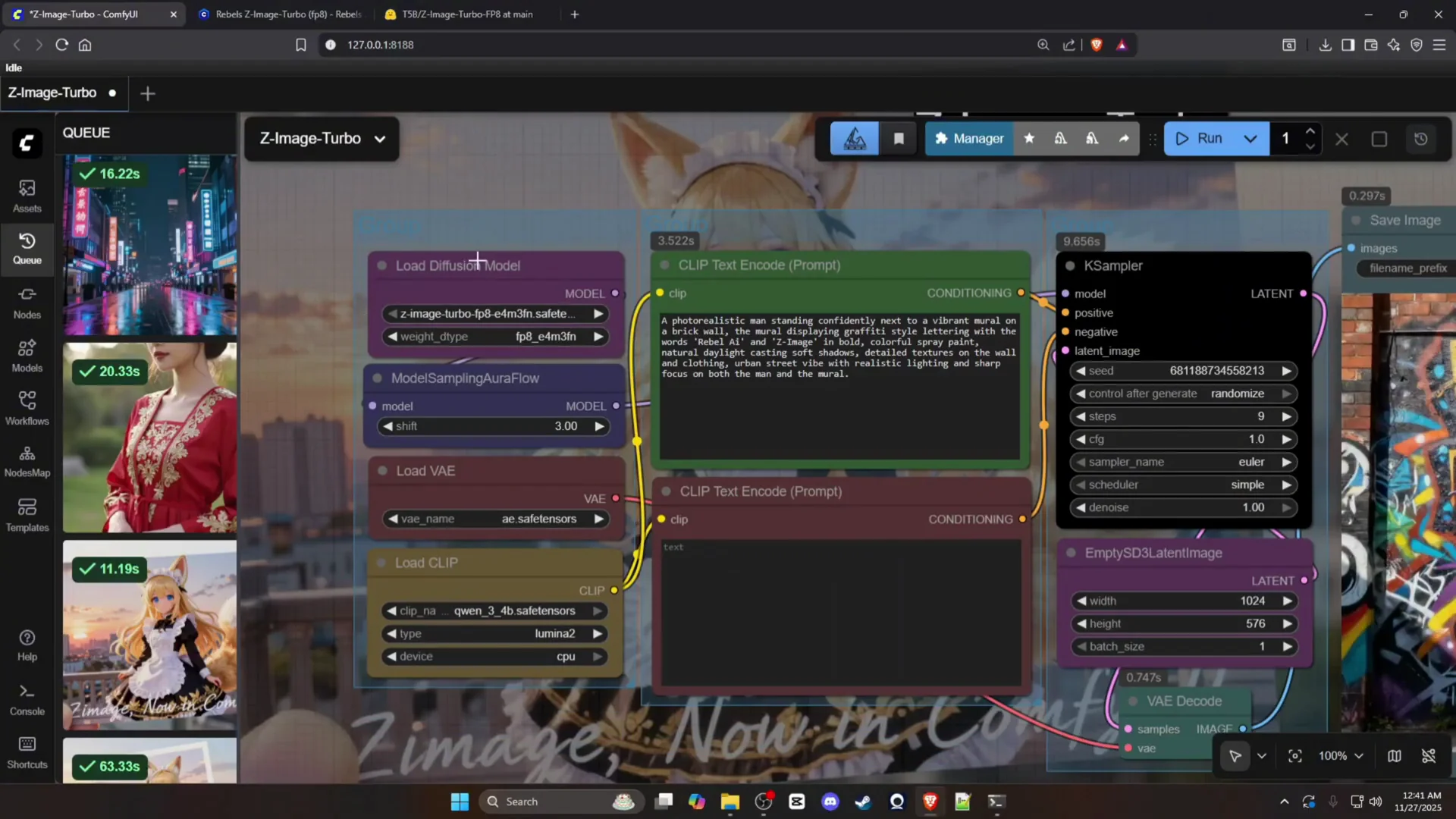
3. Load the workflow in ComfyUI
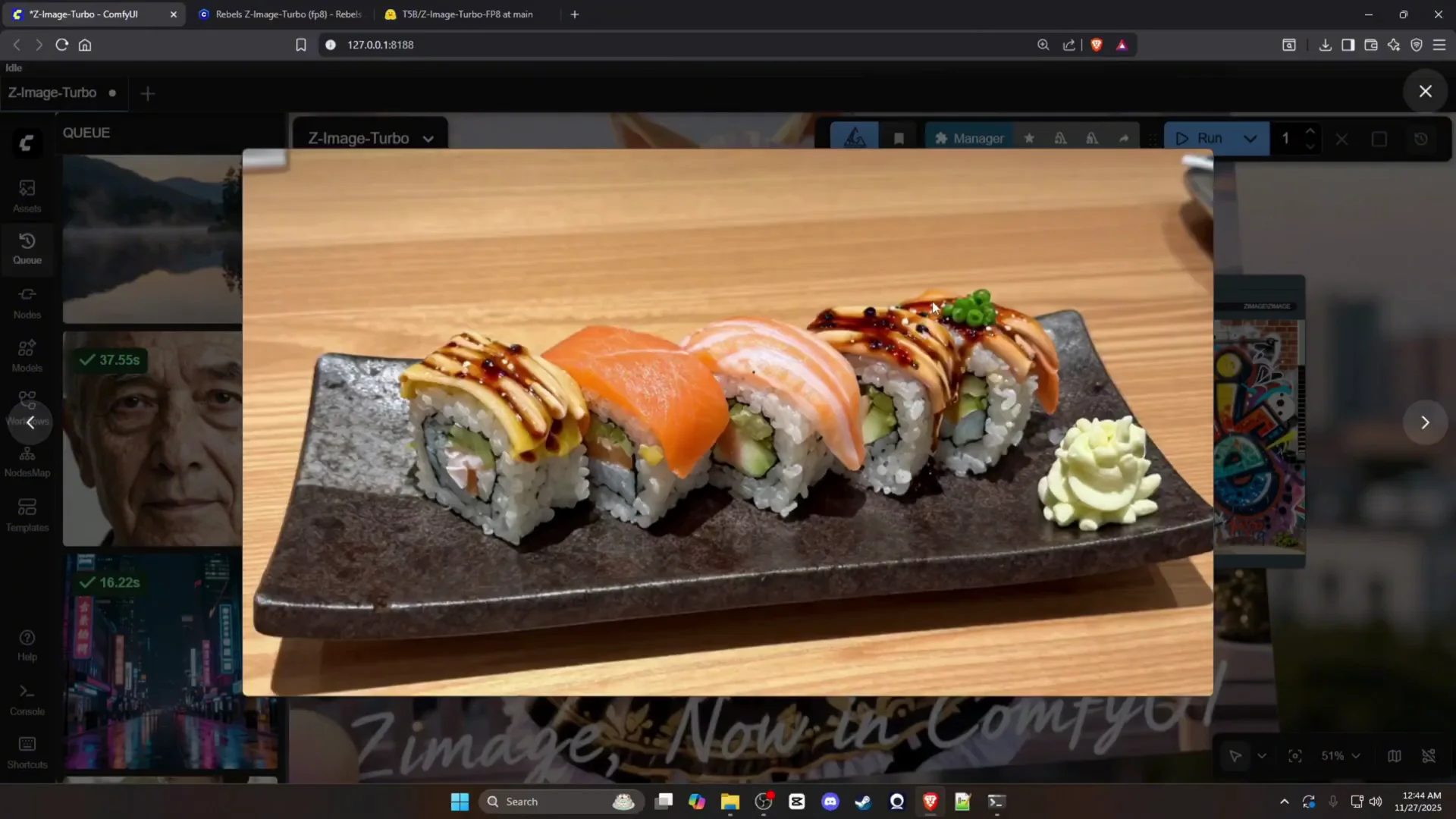
- Launch ComfyUI.
- Drag and drop the workflow file into ComfyUI.
- You will see a straightforward graph with the following components:
- Diffusion model
- Sampling flow
- VAE
- CLIP
- Two text encode nodes
- KSampler
- Empty latent image
- Decode
- Save image
4. Set the CLIP configuration correctly
- In the CLIP node, set the CLIP type to Lumina 2.
- This configuration runs on the Qwen 3B CLIP file.
- If the CLIP type is incorrect, you may see errors or poor text handling in images.
5. Confirm the sampler and steps
- Use the KSampler node for the main sampling process.
- Set the number of steps to 8 to match the model’s distilled workflow.
- Keep other parameters at sensible defaults if the workflow already includes presets.
6. Generate images
- Provide your prompt in the text encode nodes.
- Trigger the run.
- Expect render times of about 13 seconds for many scenes on an 8 GB GPU, with a general target of under 30 seconds.
7. Troubleshoot if needed
- Black images: switch from BF16 to the FP8 model variant.
- Text issues: verify CLIP type is Lumina 2 and confirm the Qwen 3B CLIP file is in place.
- VRAM errors: reduce resolution, ensure batch size is 1, and close GPU-intensive tools.
Z-Image-Turbo in Practice
Performance and speed
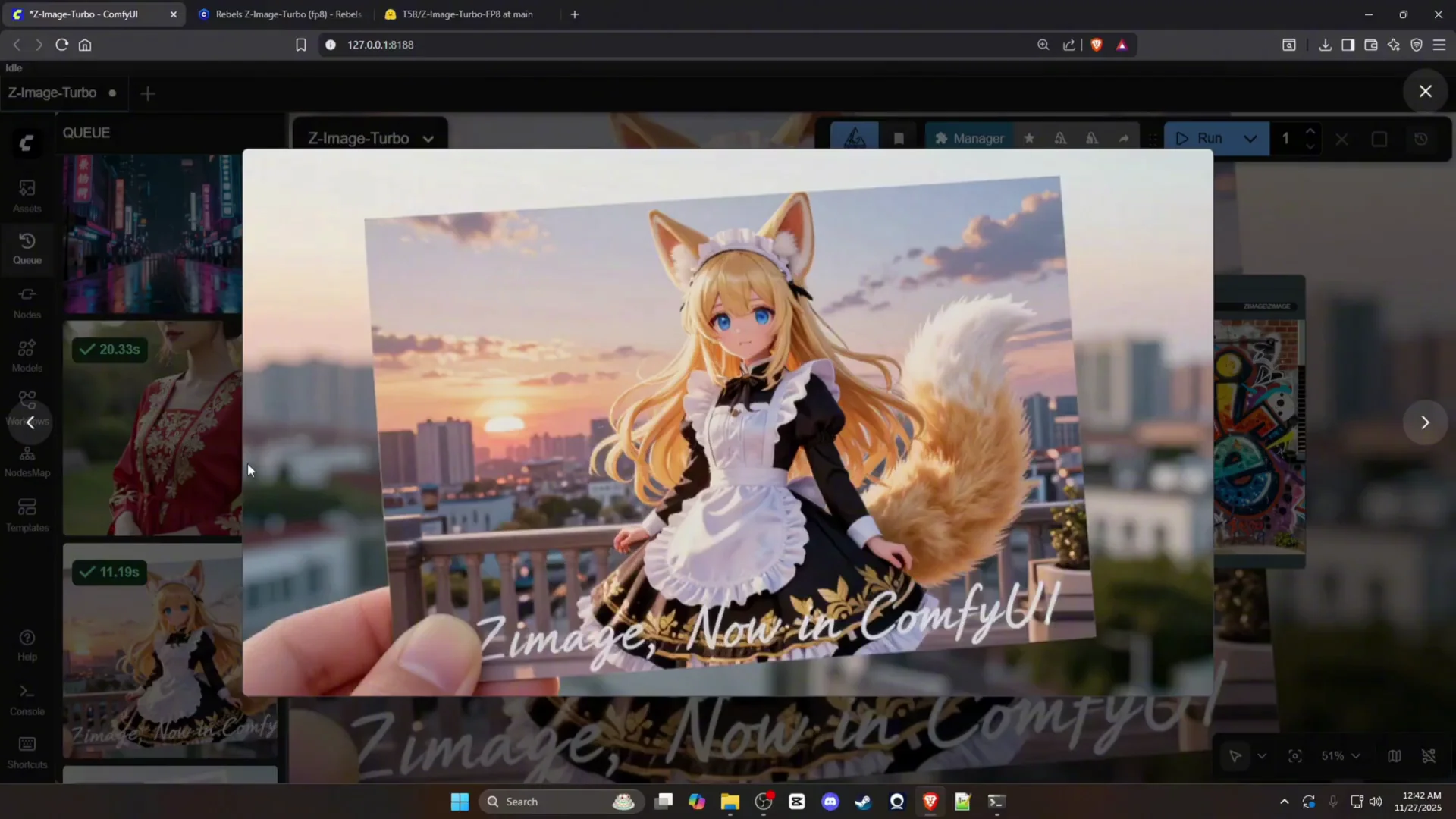
During testing, image generation finished in roughly 13 seconds for most prompts on an 8 GB GPU. That speed held across a variety of subject types, including portraits, street scenes, animals, and product-style compositions. The eight-step design aligns with the results, keeping total runtime low while maintaining detail.
Output quality
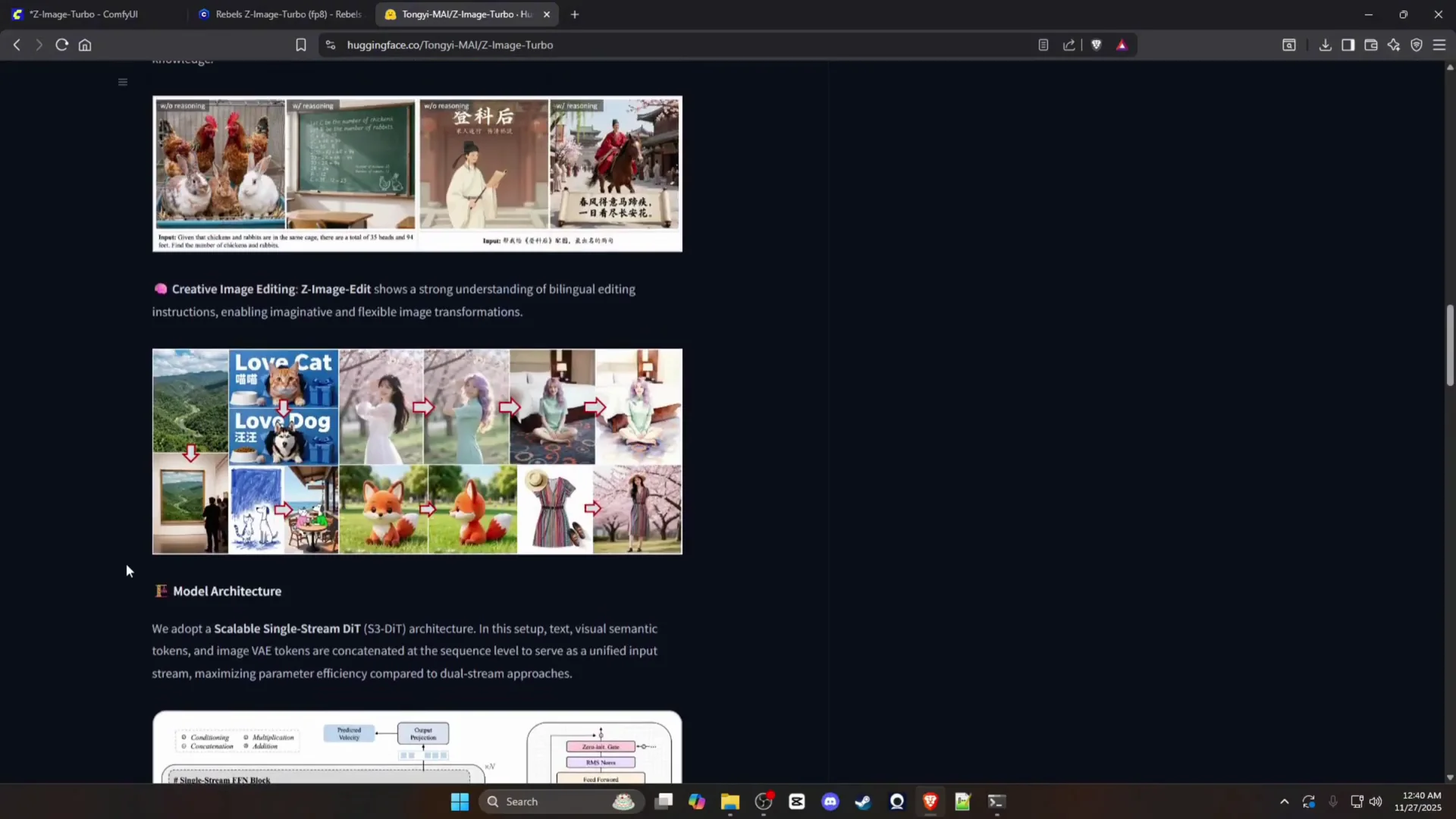
The model produced clean, sharp outputs with reliable subject structure. Facial details, fabric, and object contours were handled well. It also produced strong textures and lighting in indoor and outdoor scenes without visible artifacts.
Text rendering
Text rendering was a standout. Signs and billboards rendered cleanly, and multi-word phrases were legible. Tests with graffiti and poster-style elements produced readable text with accurate spacing and character formation.
Workflow Components Explained
Diffusion model and sampling flow
- Diffusion model: the core checkpoint that defines how images are generated from noise guided by your text prompts.
- Sampling flow: manages the inference path through the diffusion model. The eight-step design is central to the workflow’s speed.
VAE and latent path
- VAE: encodes and decodes images between pixel space and latent space.
- Empty latent image: creates the starting latent for sampling.
- Decode: brings the final latent back to RGB space for saving.
CLIP and text encoders
- CLIP node: must be set to Lumina 2 and backed by the Qwen 3B CLIP file for proper text understanding.
- Two text encode nodes: handle prompt and negative prompt, shaping image content and suppressing unwanted elements.
KSampler and save
- KSampler: runs the core denoising steps. Set steps to 8 for best speed-quality balance with this model.
- Save image: writes the final image to disk.
VRAM and Configuration Notes
FP8 vs BF16
- FP8 model: recommended. It is about 6 GB and stable in testing.
- BF16 model: produced black images during repeated trials. Skip this variant for low VRAM systems.
Text encoder VRAM
- The text encoder can consume around 8 GB of VRAM.
- If your GPU has 8 GB, be mindful of:
- Resolution settings
- Batch size
- Any other GPU usage in the background
Reliable operation checklist
- Use FP8 checkpoint
- Set steps to 8
- CLIP type: Lumina 2
- CLIP file: Qwen 3B
- Batch size: 1
- Keep other GPU apps closed
Observed Results Across Common Prompts
The following categories summarize what the workflow produced during testing.
Everyday scenes
- Street and city scenes at night rendered clean lighting, reflections, and signage.
- Cafe interiors and desks showed detailed surfaces, plants, and objects with accurate shadows and highlights.
- Vehicles, including sports cars and vintage convertibles, rendered with clean body lines and reflections.
Portraits and people
- Elderly subjects displayed crisp wrinkles and skin detail without over-smoothing.
- Standing and seated poses maintained consistent anatomy and clothing folds.
- Group shots, including couples holding hands, preserved correct body alignment and connection points.
Wildlife and objects
- Animals such as a lion displayed strong fur detail and facial structure.
- Everyday objects, including a laptop, were rendered with plausible layout and screen content.
Surreal and conceptual
- Abstract compositions like crystals in water, desert pianos, and vine-based figures retained structure and clean edges.
- Complex forms, such as seashell-style architecture, held their shapes without unwanted distortions.
Text in images
- Billboards and posters rendered text cleanly and in the correct location.
- Graffiti-style text remained legible and maintained the letter shapes defined in the prompt.
Tips for Stable, Fast Results
- Keep steps at 8 unless your prompt needs refinement. The distilled model is designed for short runs.
- Use the FP8 model checkpoint to avoid instability and VRAM pressure.
- Verify CLIP type and CLIP file as a first step if text handling looks off.
- Start with moderate image sizes before pushing resolution higher.
- Save and version your successful settings so you can return to them quickly.
Frequently Asked Setup Questions
Do I need exactly 8 steps?
Eight steps are the model’s intended operating point. It produces fast results with strong detail at that setting. You can experiment, but eight steps provide a reliable baseline.
What if I only have 8 GB of VRAM?
You can still run the workflow. Use the FP8 checkpoint, batch size 1, moderate resolution, and keep other GPU loads closed. The text encoder can be the limiting factor, so watch your memory use.
Why do I get black images?
This happened with the BF16 checkpoint during testing. Switching to the FP8 model resolved it.
Why does my text look wrong?
Check the CLIP node:
- Type must be Lumina 2
- CLIP file should be the Qwen 3B variant
Quick Reference - Z-Image-Turbo Settings
- Model: FP8 Z-Image-Turbo checkpoint
- Steps: 8
- CLIP type: Lumina 2
- CLIP file: Qwen 3B
- VRAM: 8 GB target
- Batch size: 1
- Nodes: diffusion model, sampling flow, VAE, CLIP, two text encoders, KSampler, empty latent, decode, save image
Conclusion
Z-Image-Turbo delivers fast, stable image generation with an eight-step workflow that works well on 8 GB GPUs. The single-stream token design, FP8 checkpoint, and correct CLIP configuration are the keys to its speed and reliability. With the provided ComfyUI workflow, you can set it up in minutes, generate images in about 13 seconds, and achieve clear results across portraits, scenes, objects, and signage.
Load the FP8 model, set the CLIP node to Lumina 2 with the Qwen 3B file, keep steps at 8, and start creating.
Recent Posts

How to Improve Text on Z-Image Turbo?
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image-De-Turbo de-distilled variant of Z-Image
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image Turbo ControlNet Workflow
Tutorial on Union ControlNet in ComfyUI—pose, Canny, and depth controls, depth-model preprocessing, step-by-step workflow, plus speed tests with example results.
Comments
Loading comments...