Z‑Image Turbo Guide: Install Locally and Create Stunning AI Art

Z-Image Turbo is a new image generation and editing model designed for high speed and strong instruction following. In this guide, I install it locally, explain how it works, and validate its performance with text prompts, photorealistic outputs, and text rendering. I also cover the model family, memory needs, and the architecture decisions that make it efficient.
I ran Z-Image Turbo on Ubuntu with a single NVIDIA RTX A6000 48 GB GPU, created a clean Python environment, installed Diffusers from source, and generated images inside a Jupyter notebook. Below, you will find a clear walk-through of that workflow, along with observations about quality, speed, and VRAM usage.
The goal is to replicate a practical, repeatable setup, then test claims about speed in 8 to 9 steps, strong text and bilingual handling, and efficient GPU memory usage.
What is Z-Image Turbo?
Z-Image Turbo is part of a new family of text-to-image and image editing models focused on fast inference and efficient parameter usage. It is designed to:
- Generate high quality images in as few as 8 steps, with measured subsecond to a few seconds per image on a high end GPU
- Follow instructions closely for composition, style, and subject detail
- Render complex text reliably in English and Chinese
- Operate with lower VRAM than some recent large models
The family includes Z-Image Base for general generation and Z-Image Edit for image-to-image editing. Z-Image Turbo is the fast variant tuned for quick sampling and responsive iteration. At the time of testing, the edit model had not yet been released as open source.
Z-Image Turbo Overview
Z-Image Turbo focuses on high throughput without trading away detail. The model size is roughly 32.8 GB to download. On an RTX A6000 48 GB, I observed under 25 GB VRAM consumption while sampling at the recommended 9 steps. Typical generation took roughly 4 seconds per image at 9 steps.

Below is a compact overview and a reference comparison to a recent large model many users know.
Z-Image Turbo Overview
- Model family: Z-Image Base, Z-Image Turbo, Z-Image Edit
- Primary task: Text-to-image generation
- Secondary task: Editing capability available in the series
- Notable strengths: Speed in 8 to 9 steps, photorealistic subjects, bilingual text rendering
- Tested OS and hardware: Ubuntu, single RTX A6000 48 GB
- Observed VRAM use: Under 25 GB
- Model download size: About 32.8 GB
Quick comparison
| Item | Z-Image Turbo | A recent large text-to-image model |
|---|---|---|
| Typical inference steps | 8 to 9 | 20 to 30 |
| Single image speed on high end GPU | Around 4 seconds at 9 steps | Often slower at similar resolution |
| VRAM usage (tested) | Under 25 GB | Around 60 GB in a comparable full setting noted previously |
| Text rendering | Strong in English and Chinese | Varies by model |
| Instruction following | Strong | Varies by model |
Note: Table values are based on live testing in this setup. Actual results depend on GPU, precision, and pipeline configuration.
Key Features
- Fast sampling in as few as 8 steps
- Strong instruction following for composition, style, and detail
- Photorealistic rendering across people, objects, and scenes
- Complex text handling in English and Chinese
- Efficient VRAM use compared to some large models at similar quality
- Integrated support through a dedicated Diffusers pipeline

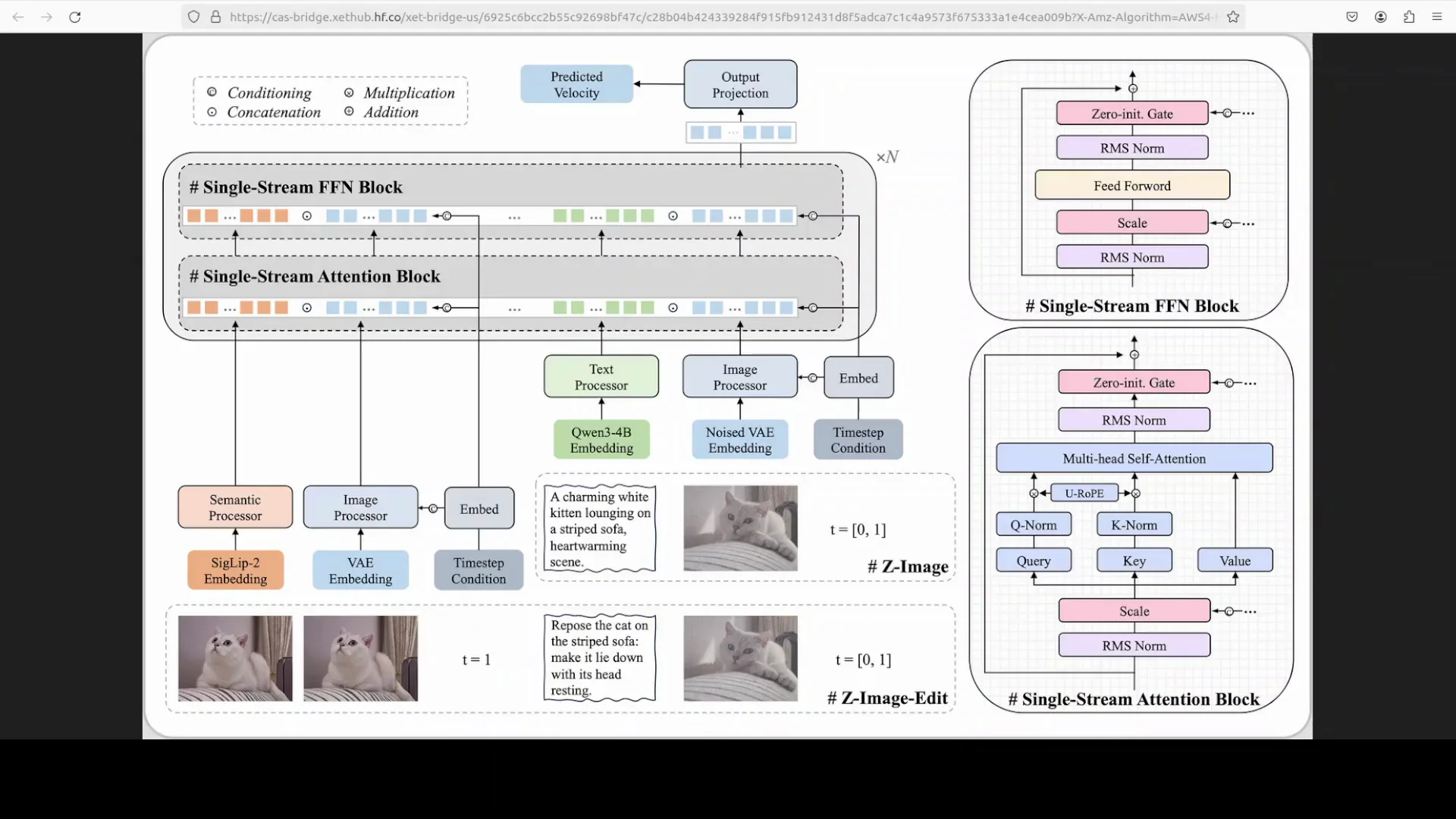
Architecture of Z-Image Turbo
The S3DIT approach

The model uses a scalable single stream diffusion transformer, often referenced as S3DIT. Instead of shipping text and images through separate pathways, it converts all inputs into a unified sequence of data tokens so the network reasons over a single stream.
This structure helps the model learn alignment between text and image tokens in one pass, which contributes to its speed and efficient parameter usage.

Core components

- Text processor: Encodes the prompt
- Semantic processor: SIGLIP is used to understand image semantics
- Image processor: A variational autoencoder compresses image information into a compact latent form
The unified token sequence is processed through repeated transformer blocks with multi head self attention.
Why this matters
Single stream tokenization and a shared latent space help reduce overhead, keep attention focused, and improve scaling. We have seen a broader move toward unified latent processing in recent multimodal work, largely to improve speed and reduce cost at inference.
Z-Image-Turbo Local Installation and Setup
Below is the same workflow I used to install and run Z-Image Turbo locally. It assumes a Linux system with a recent NVIDIA driver, CUDA support, and a high memory GPU.
1. Create and activate a virtual environment
- Python 3.10 or newer is recommended
- Use venv or conda based on your preference
Example with venv:
- python3 -m venv .venv
- source .venv/bin/activate
2. Install PyTorch with CUDA
Install the GPU build appropriate for your CUDA and driver. Check the official PyTorch site for the right command for your system.
- pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu121
Adjust the CUDA URL if you use a different version.
3. Install Diffusers from source
Z-Image Turbo is currently supported through the latest Diffusers. Installing from source ensures you get the newest pipeline.
- pip install git+https://github.com/huggingface/diffusers
- pip install transformers accelerate safetensors sentencepiece huggingface-hub
If you plan to use Jupyter:
- pip install jupyter ipykernel
- python -m ipykernel install --user --name zimage-turbo-best
4. Launch Jupyter and prepare your notebook
- jupyter notebook
Create a new Python notebook and select the environment kernel you just installed.
5. Download the model
The model is about 32.8 GB. Ensure you have enough disk space and a steady connection. The first run will trigger the download via the Diffusers pipeline. The download can take a while on slower connections.
Generating Images with Z-Image Turbo
Load the pipeline
Diffusers exposes a dedicated pipeline for Z-Image. If you hit issues with the specialized pipeline in your environment, AutoPipelineForText2Image can work as a fallback.
Basic structure in Python:
- from diffusers import ZImagePipeline
- import torch
- pipe = ZImagePipeline.from_pretrained("path_or_repo", torch_dtype=torch.float16)
- pipe = pipe.to("cuda")
Fallback option:
- from diffusers import AutoPipelineForText2Image
- pipe = AutoPipelineForText2Image.from_pretrained("path_or_repo", torch_dtype=torch.float16).to("cuda")
Notes:
- Use float16 on GPUs that support it to reduce VRAM
- If you see out of memory, try attention slicing or CPU offload
- The download occurs on first run if the model is remote
Recommended inference settings
The model authors recommend around 8 to 9 steps for fast generation. In testing, 9 steps offered a good balance of quality and speed. Guidance was set low in my tests to match the setup described.
Key parameters:
- num_inference_steps: 9
- guidance scale: low or zero
- image size: set to match your target output and available VRAM
- seed: set for repeatability
Generate an image
General pattern:
- prompt = "your prompt here"
- image = pipe(prompt, num_inference_steps=9, guidance_scale=0).images[0]
- image.save("output.png")
You can run this in a notebook to preview results inline:
- display(image)
Performance Notes
Speed
On an RTX A6000 48 GB, the model produced a 9 step image in about 4 seconds, measured from the call to the returned image. This can vary with resolution, precision, and background load, but the fast path is consistent with the model’s design.
VRAM consumption
Peak VRAM was under 25 GB at 9 steps in my tests. This is noticeably lower than some recent large models, which have hit around 60 GB in comparable full settings.
Practical implications:
- 24 GB GPUs should be able to run moderate resolutions with careful settings
- 48 GB GPUs have comfortable headroom for larger resolutions or multiple concurrent generations
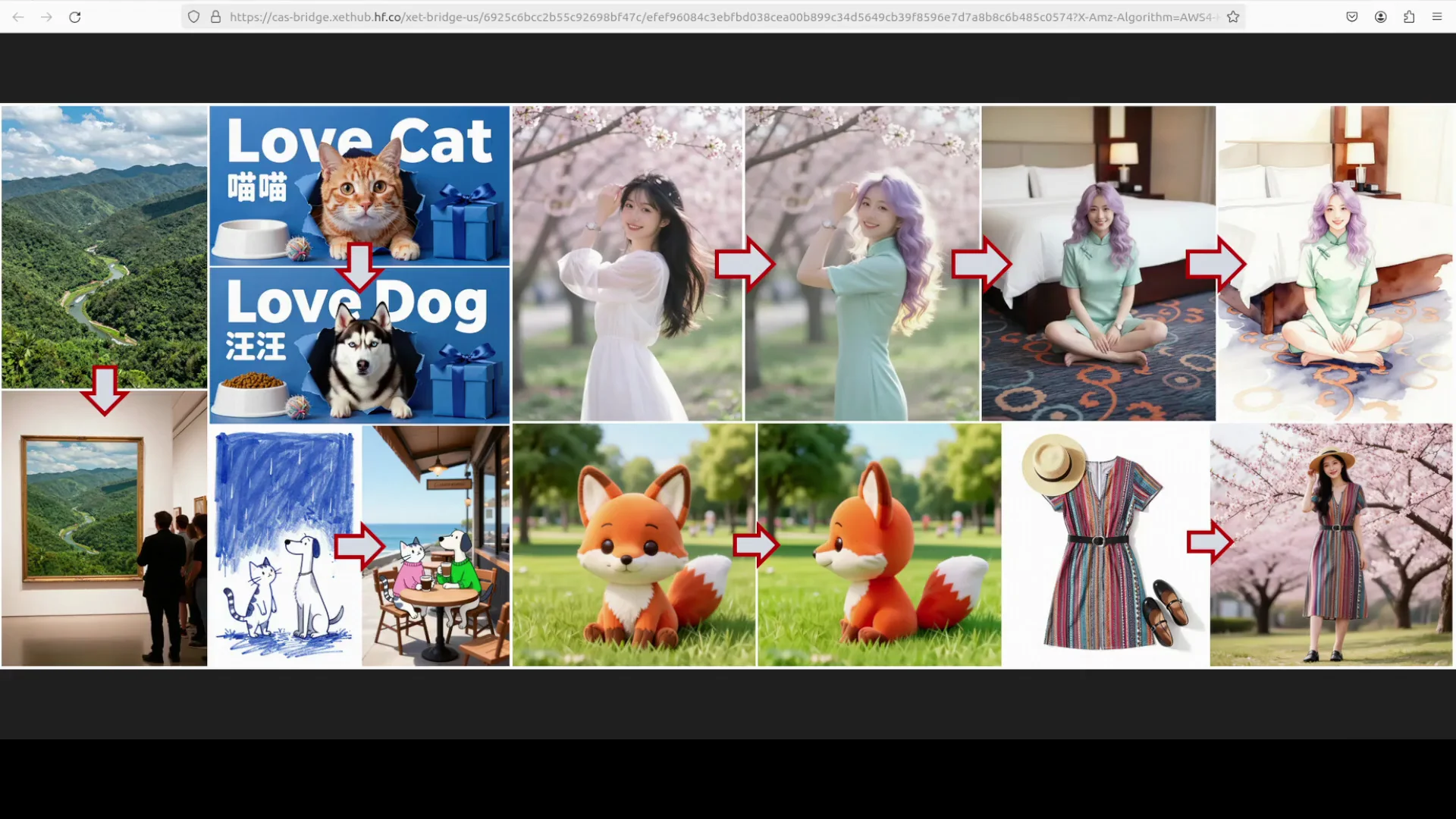
Quality observations
- People: Strong detail in face structure, skin texture, and hands, with consistent pose and anatomy
- Objects and materials: Sharp micro detail, reflective surfaces, and convincing textures
- Backgrounds and lighting: Stable composition with cohesive lighting and color tones
- Instruction following: Prompts with specific attire, setting, mood, and shot type were followed closely
Text Rendering and Language Support
Z-Image Turbo handled text prompts and signs well, with reliable output in English and Chinese. In a test with a human holding a sign, the model produced near correct text with minor issues:
- Occasional repeated word or small case mismatch
- Layout and spacing were consistent with the request
- Readability was high at a reasonable resolution
Tips to improve text rendering:
- Keep text short and specific
- Add font or sign context in the prompt
- Use a seed for repeatability
- If you see repetition, lower guidance further and retry
Family Models and Availability
The Z-Image series includes:
- Z-Image Base: General purpose text-to-image
- Z-Image Turbo: Fast variant optimized for low step counts
- Z-Image Edit: Image-to-image editing model fine tuned for creative edits
As of testing, Z-Image Edit was not yet generally available as open source. When it is released, it should follow a similar pipeline approach for local use.
Step-by-Step Guide to Reproduce My Z-Image-Turbo Setup
1. System and environment
- OS: Ubuntu
- GPU: RTX A6000 48 GB
- CUDA: Recent version compatible with your driver
- Python: 3.10 or newer
Steps:
- python3 -m venv .venv
- source .venv/bin/activate
- pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu121
- pip install git+https://github.com/huggingface/diffusers
- pip install transformers accelerate safetensors sentencepiece huggingface-hub
- pip install jupyter ipykernel
- python -m ipykernel install --user --name zimage-turbo-best
2. Launch Jupyter
- jupyter notebook
- Create a new notebook and select the zimage-turbo-best kernel
3. Load the model and generate
In the notebook:
- from diffusers import ZImagePipeline
- import torch
- pipe = ZImagePipeline.from_pretrained("path_or_repo", torch_dtype=torch.float16).to("cuda")
- prompt = "your prompt"
- image = pipe(prompt, num_inference_steps=9, guidance_scale=0).images[0]
- image.save("sample.png")
If you need a generic pipeline:
- from diffusers import AutoPipelineForText2Image
- pipe = AutoPipelineForText2Image.from_pretrained("path_or_repo", torch_dtype=torch.float16).to("cuda")
Notes:
- First run will download about 32.8 GB
- Keep guidance low for closer alignment with the recommendations used here
- Increase or decrease steps to balance speed and quality
Practical Tips for Best Results
- Use float16 precision on compatible GPUs to reduce VRAM
- Keep num_inference_steps around 8 to 9 for speed, increase slightly if you need more detail
- For text on signs or labels, add context about the surface, font vibe, and lighting
- Run with a fixed seed to compare settings consistently
- If VRAM is tight, reduce resolution first, then try attention slicing or CPU offload
- Save intermediate outputs so you can compare effects of step counts and guidance
Troubleshooting
- Out of memory
- Reduce resolution
- Lower batch size to 1
- Use float16 and enable attention slicing
- Close other GPU processes
- Slow downloads
- Ensure enough free disk space and a stable connection
- Pre-download the model during off-peak times
- Visual artifacts
- Bump num_inference_steps slightly
- Adjust guidance down or up in small increments
- Refine the prompt to be specific and concise
Results Summary
From setup through testing, Z-Image Turbo delivered on speed and quality in a local environment:
- Sub 5 second single image generation at 9 steps on a high end GPU
- Under 25 GB VRAM usage in the tested configuration
- Strong instruction following for detailed prompts
- Reliable text rendering in English and Chinese with minor edge cases
The single stream diffusion transformer design, unified tokenization, and well chosen components make this model efficient at inference while keeping quality high.
Conclusion
Z-Image Turbo is a fast, capable text-to-image model that runs well on a single high memory GPU with sensible settings. The installation is straightforward with Diffusers from source, and the pipeline delivers quick results at around 9 steps. Photorealistic generation, consistent instruction following, and bilingual text handling stand out.
The broader Z-Image family shows a clear focus on efficiency and practical deployment. As the editing model becomes available, it will be worth exploring the same local workflow for high quality image-to-image work.
Recent Posts

How to Improve Text on Z-Image Turbo?
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image-De-Turbo de-distilled variant of Z-Image
Z-Image-De-Turbo: A de-distilled variant of Z-Image-Turbo for flexible training, LoRA development, and extended experimentation without adapters.

Z-Image Turbo ControlNet Workflow
Tutorial on Union ControlNet in ComfyUI—pose, Canny, and depth controls, depth-model preprocessing, step-by-step workflow, plus speed tests with example results.
Comments
Loading comments...